Pre-Training with Whole Word Masking for Chinese BERT
Published in IEEE/ACM Transactions on Audio, Speech, and Language Processing (TASLP), Vol.29, 2021
Authors
Yiming Cui, Wanxiang Che, Ting Liu, Bing Qin, Ziqing Yang
Highlights
- 🎉 ESI Highly Cited Papers in Engineering by Clarivate™.
- 🎉 Top-25 Downloaded Papers in IEEE Signal Processing Society (2021-2023).
- 🎉 IEEE SPS Best Paper Award (2025).
Resources
📄 PDF
🔎 Bib
IEEE Xplore
Chinese-BERT-wwm
MacBERT
Abstract
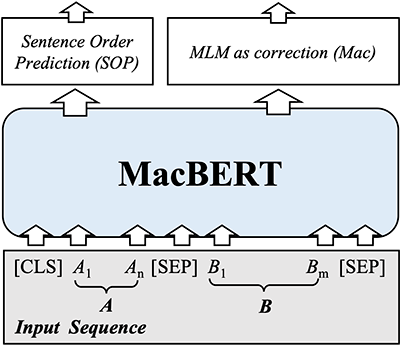
Bidirectional Encoder Representations from Transformers (BERT) has shown marvelous improvements across various NLP tasks, and its consecutive variants have been proposed to further improve the performance of the pre-trained language models. In this paper, we aim to first introduce the whole word masking (wwm) strategy for Chinese BERT, along with a series of Chinese pre-trained language models. Then we also propose a simple but effective model called MacBERT, which improves upon RoBERTa in several ways. Especially, we propose a new masking strategy called MLM as correction (Mac). To demonstrate the effectiveness of these models, we create a series of Chinese pre-trained language models as our baselines, including BERT, RoBERTa, ELECTRA, RBT, etc. We carried out extensive experiments on ten Chinese NLP tasks to evaluate the created Chinese pre-trained language models as well as the proposed MacBERT. Experimental results show that MacBERT could achieve state-of-the-art performances on many NLP tasks, and we also ablate details with several findings that may help future research. We open-source our pre-trained language models for further facilitating our research community.