Efficient and Effective Text Encoding for Chinese LLaMA and Alpaca
Published in arXiv pre-print: 2304.08177, 2023
Authors
Yiming Cui, Ziqing Yang, Xin Yao
Highlights
- 🎉 The open-source projects have been ranked 1st place in GitHub Trending repositories.
Resources
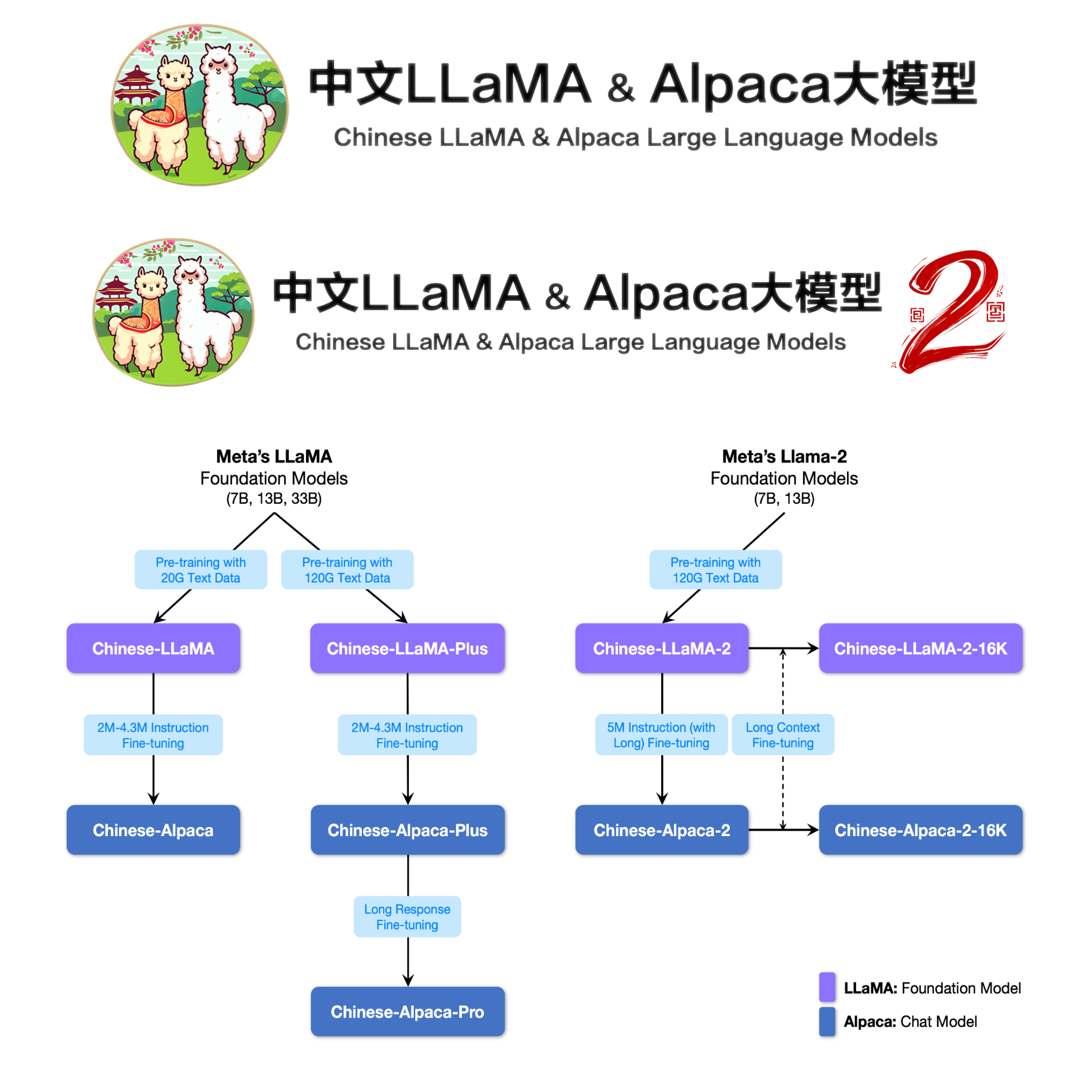
📄 PDF 🔎 Bib arXiv Chinese-LLaMA-Alpaca Chinese-LLaMA-Alpaca-2 Chinese-LLaMA-Alpaca-3
Abstract
Large Language Models (LLMs), such as ChatGPT and GPT-4, have dramatically transformed natural language processing research and shown promising strides towards Artificial General Intelligence (AGI). Nonetheless, the high costs associated with training and deploying LLMs present substantial obstacles to transparent, accessible academic research. While several large language models, such as LLaMA, have been open-sourced by the community, these predominantly focus on English corpora, limiting their usefulness for other languages. In this paper, we propose a method to augment LLaMA with capabilities for understanding and generating Chinese text and its ability to follow instructions. We achieve this by extending LLaMA’s existing vocabulary with an additional 20,000 Chinese tokens, thereby improving its encoding efficiency and semantic understanding of Chinese. We further incorporate secondary pre-training using Chinese data and fine-tune the model with Chinese instruction datasets, significantly enhancing the model’s ability to comprehend and execute instructions. Our experimental results indicate that the newly proposed model markedly enhances the original LLaMA’s proficiency in understanding and generating Chinese content. Additionally, the results on the C-Eval dataset yield competitive performance among the models with several times the size of ours. We have made our pre-trained models, training scripts, and other resources available through GitHub, fostering open research for our community.