Evaluating Large Language Models on Multimodal Chemistry Olympiad Exams
Published in Communications Chemistry, 8, 402. Nature Portfolio, 2025
Authors
Yiming Cui, Xin Yao, Yuxuan Qin, Xin Li, Shijin Wang, Guoping Hu
Resources
Abstract
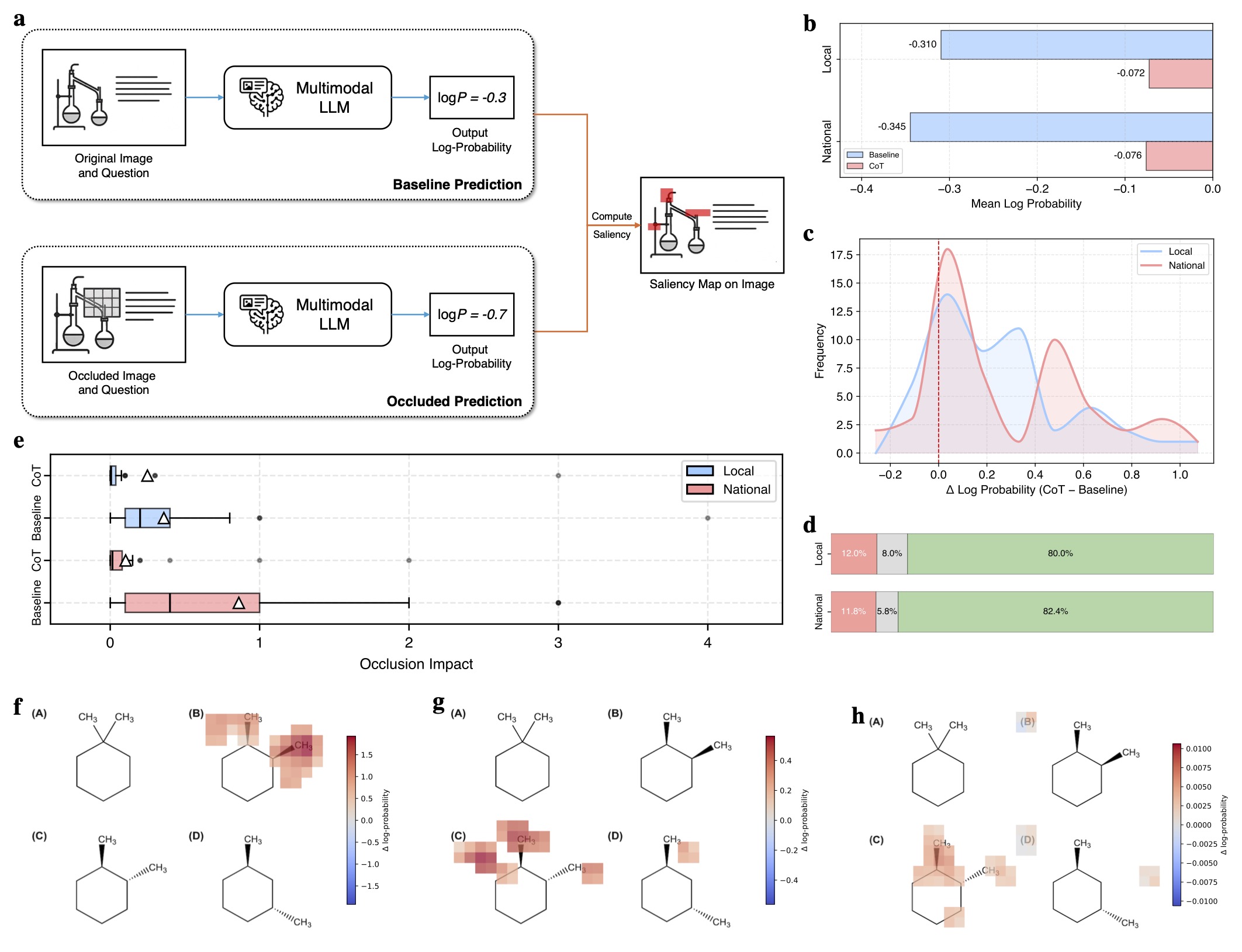
Multimodal scientific reasoning remains a significant challenge for large language models (LLMs), particularly in chemistry, where problem-solving relies on symbolic diagrams, molecular structures, and structured visual data. Here, we systematically evaluate 40 proprietary and open-source multimodal LLMs, including GPT-5, o3, Gemini-2.5-Pro, and Qwen2.5-VL, on a curated benchmark of Olympiad-style chemistry questions drawn from over two decades of U.S. National Chemistry Olympiad (USNCO) exams. These questions require integrated visual and textual reasoning across diverse modalities. We find that many models struggle with modality fusion, where in some cases, removing the image even improves accuracy, indicating misalignment in vision-language integration. Chain-of-Thought prompting consistently enhances both accuracy and visual grounding, as demonstrated through ablation studies and occlusion-based interpretability. Our results reveal critical limitations in the scientific reasoning abilities of current MLLMs, providing actionable strategies for developing more robust and interpretable multimodal systems in chemistry. This work provides a timely benchmark for measuring progress in domain-specific multimodal AI and underscores the need for further advances at the intersection of artificial intelligence and scientific reasoning.